
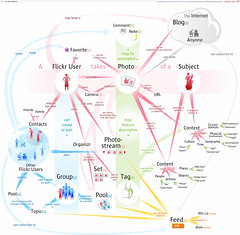
A diagram of what Flickr is about. Stunning!
How I’d love to produce this style of diagram instead of those boring UML things to document my software …
(Via information aesthetics)
A diagram of what Flickr is about. Stunning!
How I’d love to produce this style of diagram instead of those boring UML things to document my software …
(Via information aesthetics)
Productivity blogger Merlin Mann of 43Folders tells the story (audio, 10:50 min) of how he ended up not writing the “Life Hacks” book for O’Reilly. A great warning to all fellow procrastinators, especially those who like to endlessly fiddle with their organization systems.
Paraphrased from this Cory Doctorow piece:
New technologies succeed by being good at the stuff that the old technology sucked at, not good at the stuff that made the old technology great.
This happens to be a one-sentence summary of The Innovator’s Dilemma, the best book ever for understanding how technology changes the business world.
On 2005-06-30 Googlebot visited node 1, the leftmost node. It did not crawl the path from the root to this node, so how did it find the page? Did it guess the URL or did it follow some external link? A few hours later, Googlebot crawled node 2, which is linked as a parent node by node 1. These two nodes are displayed as a tiny dot in the animation on 2005-06-30, floating above the left branch. Then, a week later, on 2005-07-06 (two days after the attempt to find rightmost node), between 06:39:39 and 06:39:59 Googlebot finds the path to these disconnected nodes by visiting the 24 missing nodes in 20 seconds. It started at the root and found it’s way up to node 2, without selecting a right branch. In the large version of the Googlebot tree, this path is clearly visible. The nodes halfway the path were not requested for a second time and are represented by thin short line segments, hence the steep curve.
An experiment to study the major search bots, these mythical creatures of the Internet, by constructing a virtual labyrinth for them to explore, and recording their traces … The Internet is truly a strange place, with its bots and spiders and crawlers and zombies, its darknets and tunnels and backbones and honeypots. It is long past the point where any single person can grasp what’s going on out there.
William Gibson’s cyberspace can’t be far off.
(via Tim Bray)
Damian Steer of HP Labs has released the initial version of his SquirrelRDF. The project homepage is the cutest ever.
I talked about SquirrelRDF previously.
Like our D2RQ/D2R Server, SquirrelRDF enables SPARQL queries against relational database content. In addition, it also enables queries against LDAP data.
I didn’t have a chance to play with it yet, but it looks well-executed and the documentation is excellent. It will certainly help to get more data into the Semantic Web.
I also owe Damian a thank you. He gave me the source for SquirrelRDF’s ExtractConfig tool a couple of weeks ago. The code analyzes a database schema and produces a mapping configuration file. I used the code as a starting point for D2R Server’s equivalent feature, the generate-mapping script. I wouldn’t have had that feature ready in time for my www2006 demo otherwise.
From Christoph Görn: A little query form for some SIOC. The cool thing is that results are displayed instantly while you type. (Try typing the names of some Planet RDF authors, e.g. “Tim” or “Dan”.) Who says that RDF stuff has to be slow? OK, it’s just a toy dataset, but I still like it.
The Javascript-powered UI queries the backend server over SPARQL. The server is ARC, which seems to be a great choice for quick-and-dirty SPARQL endpoints on commodity PHP/MySQL webspace (SPARQL endpoint recipe from Benjamin Nowack here).
SPARQL and AJAX are a killer combination.
Chris has updated the Developers Guide to Semantic Web Toolkits for different Programming Languages. A bunch of toolkit descriptions were updated to the latest version, and the recent flurry of Javascript SPARQL clients (here, here) were added.
Paul is a friend of mine from school. In 9th grade or so we collaborated on an encryption tool based on, umm, the XOR algorithm, implemented in, umm, PowerBASIC. Hadn’t heard from him for a while – he just said hi in my comments. He writes about Java and tech stuff, with the odd soccer link thrown in for fun.
Jorge Pérez, Marcelo Arenas, Claudio Gutierrez: Semantics and Complexity of SPARQL (preprint)
SPARQL has a dirty little secret: The spec doesn’t define the formal semantics. There is a lot of language to explain how everything is supposed to work, and there are a lot of examples, but no rigorous mathematical definitions that allow one to settle weird corner cases.
That HP Labs tech report: When I was working on SPARQL-to-SQL translation at HP last year, I struggled a lot with this lack of formal semantics. I ended up creating my own – A relational algebra for SPARQL, published as an HP tech report. Unfortunately, it clearly disagreed with what Andy and the other DAWG folks had in mind in a couple of cases. And I lack the mathematical skills to write up a thorough formal definition of anything. In summary, I’m not particularily proud of the report.
Pérez et al. to the rescue: Yesterday, Claudio Gutierrez (of Temporal RDF fame) and his co-authors announced their paper at the DAWG mailing list. It’s a great piece of work. Their contributions:
a proof that both are equivalent except in a few edge cases*,
Some caveats:
FILTER conditions are discussed,FILTER conditions are restricted to the variables occuring in the containing pattern – a restriction that SPARQL doesn’t make,FILTER comparisions and ORDER BY).Why this is good news: I feel that this paper is a great formal foundation for SPARQL. It presents clear and reasonable answers to all of the weird edge cases we had to pussyfoot around until now. It makes me confident that SPARQL can be formally analyzed and there are answers to the hard optimization problems I and other people face when implementing SPARQL (e.g. in D2RQ).
On a personal level, I also feel good about it because it validates some of the inconclusive results I got last year, like the SQL translation presented in the report. I knew there were edge cases where my approach didn’t match SPARQL, and I suspected that they wouldn’t occur much in real queries – but now I know for sure, and I know that there are no further edge cases lurking.
That’s the progress of science, I suppose. I wonder how my time at HP would have gone if I had known the results of this paper a year ago. It would have saved me many weeks of unproductive headaches. But no one knew these things back then. That’s what it feels like to live on the bleeding edge of research … And I like it.
In its classic game-theoretic formulation by David Lewis, a language is defined formally but established and used according to convention. A convention is used by a community to solve some co-ordination problem, such as determining how to list dates so as to schedule meetings or record history, even if such a choice is arbitrary (the American convention of listing the month before the day as opposed to the European method of listing the day before the month). The identity and meaning of data on the Web could be viewed as a co-ordination problem. A further general idea that falls out of a game-theoretic analysis is that people will in general use the minimum amount of convention to solve their co-ordination problem. This rule-of-thumb might explain the slowness of the Web community to embrace model-theoretic semantics.
(emphasis mine)
I was in the audience at Harry’s IRW2006 talk, and that little gem stuck with me. The Semantic Web (and the web in general) is a co-ordination problem among a large number of publishers and consumers of information that do minimal communication with each other.
“Building the Semantic Web,” then, means to me, “Identifying a minimal set of practices that enable large-scale interoperability of RDF data.”